Public institutions publish more text every year than any human team can read. The French Competition Authority (FCA) alone released over 800 pages of decisions in 2025, and the historical archive holds ~1,900 decisions going back to the year 2000. Each decision is 30 to 300+ pages of dense French legal prose, packed with the exact numbers economists want — fines, dates, recidivism flags, leniency reductions, procedural counts — and none of it is ready for analysis.
To get a single number out, an economist still has to open a PDF and copy by hand. Datasets that should exist do not. Studies that should be possible are not run.
The question that drives this project is simple:
Can we make AI read these documents for us — reliably, cheaply, at scale — and then use the result?
This post is a tour of the answer I'm building. It has four parts: the pipeline, the benchmark, and — the part I'm most excited about — the agent.
1. Why not just paste the PDF into ChatGPT?
That's the first question anyone asks, and the honest answer is: it breaks on three fronts.
- Context length. A 300-page decision blows the usable window; truncation is silent; running ~1,900 of them through long context is prohibitively expensive; and quality drops sharply on long inputs anyway.
- Not traceable. A free-form answer can't be audited. There's no field-level provenance, no way to inspect what the model attended to, and a hallucinated fine is indistinguishable from a real one.
- Not reusable. Each prompt is one-shot. You can't fix one field without redoing the whole answer; you can't join, query, or re-run analyses on yesterday's output; nothing accumulates.
What we want is the opposite: a constrained pipeline with chunked input, a typed schema, and a persistent structured store.
2. The pipeline — scrape, then structured extraction
The pipeline has two stages.
Stage 1 — Scraping & corpus construction
The scraper crawls autoritedelaconcurrence.fr, parses each decision page (id, date, sector, dispositif, parties, appeals, PDF url), downloads PDFs in parallel with retries, and — the interesting part — converts each PDF to clean Markdown using marker-pdf with Surya OCR. That last step matters: tables survive, reading order is preserved, and footnotes don't pollute the text. Markdown is what the LLM will read, so quality here propagates everywhere downstream.
The full archive converts in about 1 hour on a single NVIDIA A100 (40 GB). Everything lands in a SQLite database (fca.db) with one row per decision: 1,897 decisions today.
Stage 2 — Reconstructing the manual ground truth
To know whether an LLM is doing a good job, you need a reference. The reference combines two human-annotated sources:
- A tabular CSV (538 rows × 65 columns) — one row per prosecuted entity, with case-level fields (dispositif, dates, complainants, sector) and entity-level fields (fine, recidivism, leniency, injunctions).
- A brat span-annotation corpus (95 decisions,
.txt+.annpairs) — character offsets in the raw text, with a rich entity typology:Company(Plaintiff / Defendant),DecisionDate,AuthoritySection,ArticleNumber,Paragraph, and more.
Merged and normalized, these form the golden-truth JSON corpus: each ground-truth record is anchored both in tabular metadata and in textual spans.
How the extraction itself works
We give an LLM the markdown text plus a JSON schema (~50 fields, with types, enums, and required fields) and use structured output / constrained decoding (OpenAI's response_format=json_schema, strict=true, and the equivalents in Anthropic, Google, Mistral, vLLM, llama.cpp, Ollama). The decoder cannot emit tokens that would violate the schema. We get valid JSON by construction — no regex extraction, no malformed parses. Only structure is guaranteed, not semantic correctness, which is exactly what the benchmark is for.
3. The benchmark — 18 LLMs against the ground truth
We selected 32 fully-validated ground-truth decisions (2009–2013) and ran every model on the same task with the same prompt and the same schema — only the model changes:
- OpenAI — gpt-5.5, gpt-5.4, gpt-5.4-mini, gpt-5.4-nano, gpt-5.2
- Anthropic — claude-opus-4-7, claude-opus-4-6, claude-sonnet-4-6, claude-haiku-4-5
- Mistral — mistral-large, mistral-medium, mistral-small
- Open / Other — gemma-4-31b, gemini-3.1-flash-lite, minimax-m2.7, owl-alpha, ling-2.6-1t, grok-4.3
32 decisions × 18 models = 576 extracted JSONs in one batch.
Scoring — Gower distance
Each extracted decision gets a single number in [0, 1] (0 = perfect, 1 = nothing matches), via Gower distance that aggregates field-wise distances:
- Booleans / categoricals — 0 if equal, 1 if different.
- Integers —
|a − b| / range(field), clamped to [0, 1]. - Dates — parsed to days since 2000-01-01, then numeric distance.
- Strings (entity names) — semantic distance via BERTScore (
bert-base-multilingual-cased, French), as1 − F1.
Per decision: case-level fields each get a distance; prosecuted entities are matched 1-to-1 between ground truth and extraction and each pair is scored; the final number is the mean of all field distances.
Headline result
Out of 18 models, the top of the leaderboard was google/gemma-4-31b-it (mean Gower distance ≈ 0.169), narrowly ahead of claude-opus-4-7 and gpt-5.5. An open-source 31B model beat every proprietary frontier model on this task — which, if it holds up under a bigger evaluation, makes running on the full archive essentially free.
What's next on the benchmark side
The current numbers are encouraging, but 32 decisions is small. The roadmap is staged:
- Richer scoring — add field-level F1 and recall on top of Gower (one global number is great for ranking, but F1/recall expose where each model wins or loses).
- Bigger benchmark — re-evaluate the top-4 models on 200 decisions for tighter rankings.
- Full extraction — run the single best model over the entire archive (1,897 decisions) to produce the final dataset.
Cheap models get cut early; only survivors pay the cost of the 200-decision round; only the winner pays the full-archive cost.
4. The agent — turning JSON into insights
Once we have a clean, structured dataset, the obvious next question is: what do we do with it? And the answer used to be: "open a notebook, load the JSONs, decide on a regression, plot, restart, write up."
This is the part where I want to spend time, because it's where the work shifts from "extracting data" to "doing economics." So instead of a single notebook, I built a deep-research agent — a coworker that drafts, runs, and iterates faster than any one researcher, freeing the human for the part that matters: question design and interpretation.
The stack — LangChain, LangGraph, Deep Agents
Three nested layers, each adding what the layer below is missing:
- LangChain — common interface to LLMs and tools (
bind_tools(), structured output, prompts). Great for one-shot chains, not so great for loops. - LangGraph — agents as stateful graphs: nodes are Python functions that read and write a shared
State, edges (some conditional) decide what runs next, and cycles are allowed. That last bit is what turns a chain into a real reasoning loop. - Deep Agents — LangChain's opinionated layer on top of LangGraph: planning tool, filesystem state, sub-agents. The kit you reach for when you actually want a research agent rather than a demo.
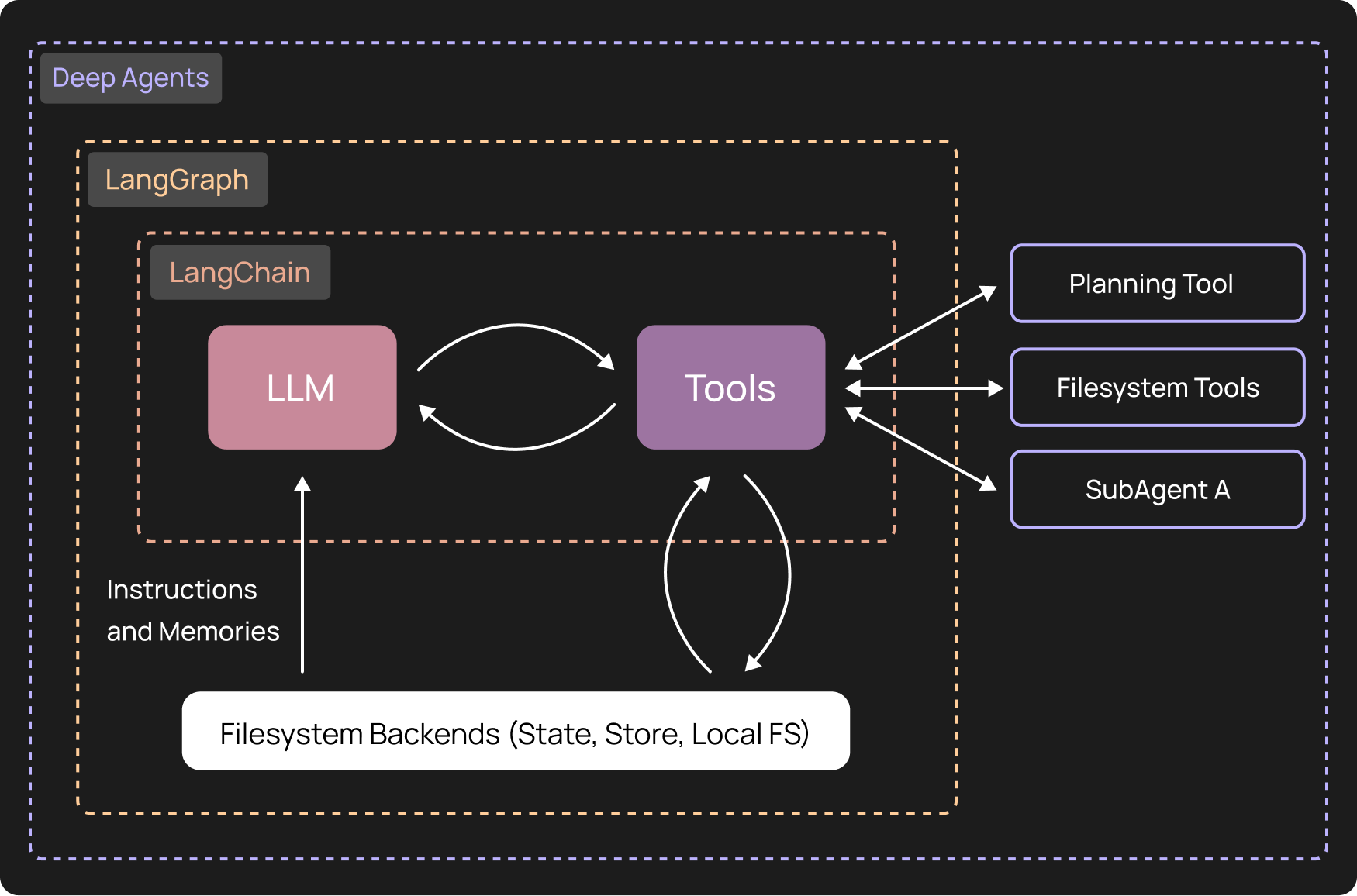
Picking a topology
LangGraph documents the canonical multi-agent topologies — single agent, network, supervisor, supervisor-as-tools, hierarchical, custom. The right shape depends on the task.
A pure single-agent setup bottlenecks on one context window. A free-for-all network is flexible but unpredictable. We went with a custom topology: an Architect node that routes between four specialised sub-agents in a loop.
Our architecture
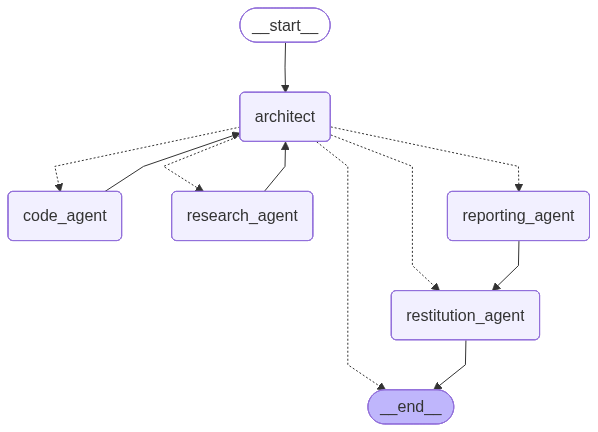
- architect — reads history, picks the next node, emits a small JSON
{ next, task }. - research_agent — explores the dataset and the web.
- code_agent — writes and runs Python in a sandbox.
- reporting_agent — writes an academic-style PDF (called once).
- restitution_agent — synthesises the final answer.
Hard cap: 10 architect cycles. After that, the graph is forced to restitution so it can't loop forever.
State — small on purpose
LangGraph only needs one thing: a shared State. Ours is deliberately tiny:
class AgentState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
next: str # routing key emitted by architect
task: str # natural-language task for next nodemessagesis append-only history with a reducer so each node can add to it.nextdecides the conditional edge afterarchitect.taskis what the picked sub-agent should actually do.
Cycles + a stop condition = a real reasoning loop, not a chain.
Each sub-agent is a ReAct agent
Inside every node, the loop is the same: Reason → Act → Observe → Loop.
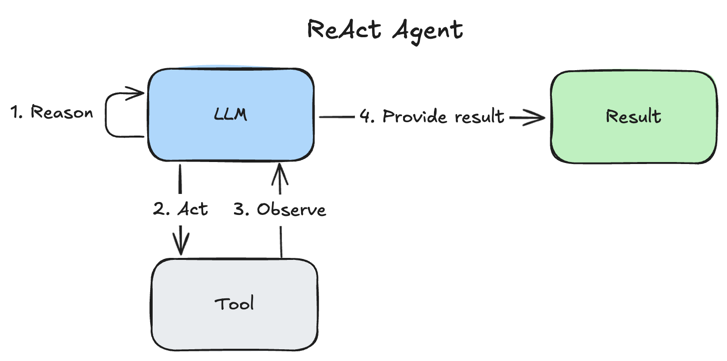
- Reason — the LLM writes a short plan: what should happen next?
- Act — it calls a tool with concrete arguments.
- Observe — the tool's output is fed back into context.
- Loop — it re-reasons over the new evidence and acts again, stopping when it has enough to answer.
The research_agent has data tools (get_all_decisions, get_decision_by_id, get_field_from_decisions, available_decisions, gliner_search for named-entity search inside a decision, and websearch as a last resort). The code_agent has a sandboxed run_python() with the whole stack pre-imported: pandas, numpy, statsmodels, scipy.stats, pingouin, sklearn, xgboost, lightgbm, matplotlib, seaborn, and xhtml2pdf for PDFs.
The architect routes — the sub-agents reason and act.
What it actually produced
In a single run on 130 ground-truth decisions, the agent:
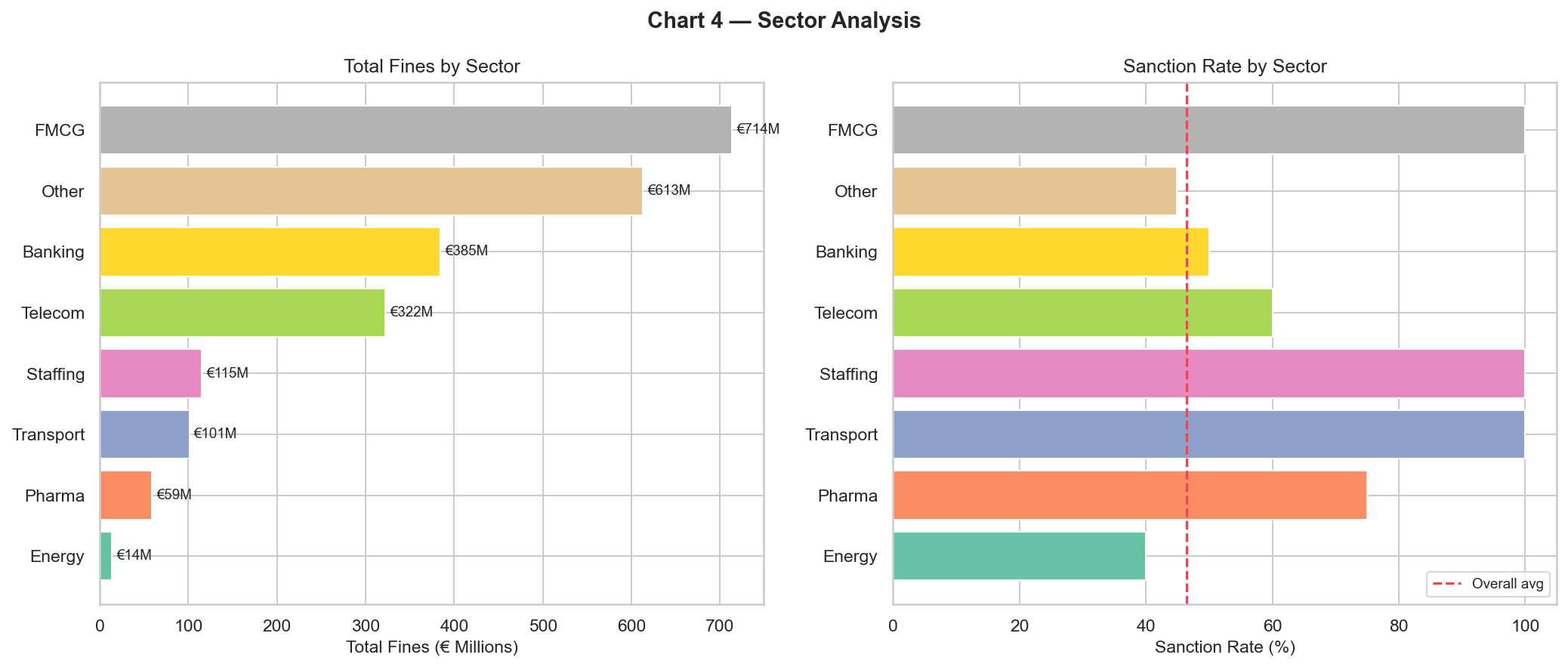
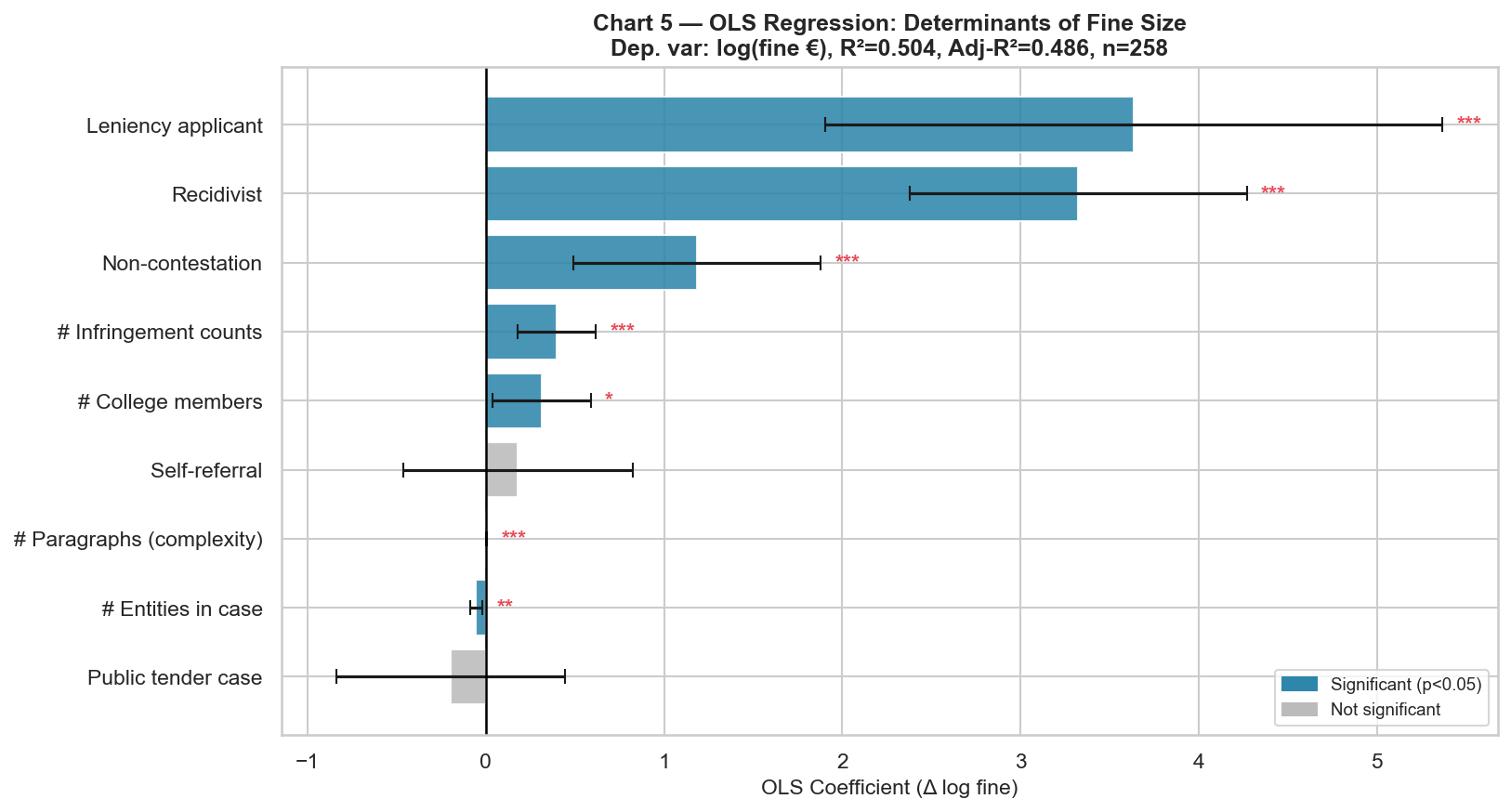
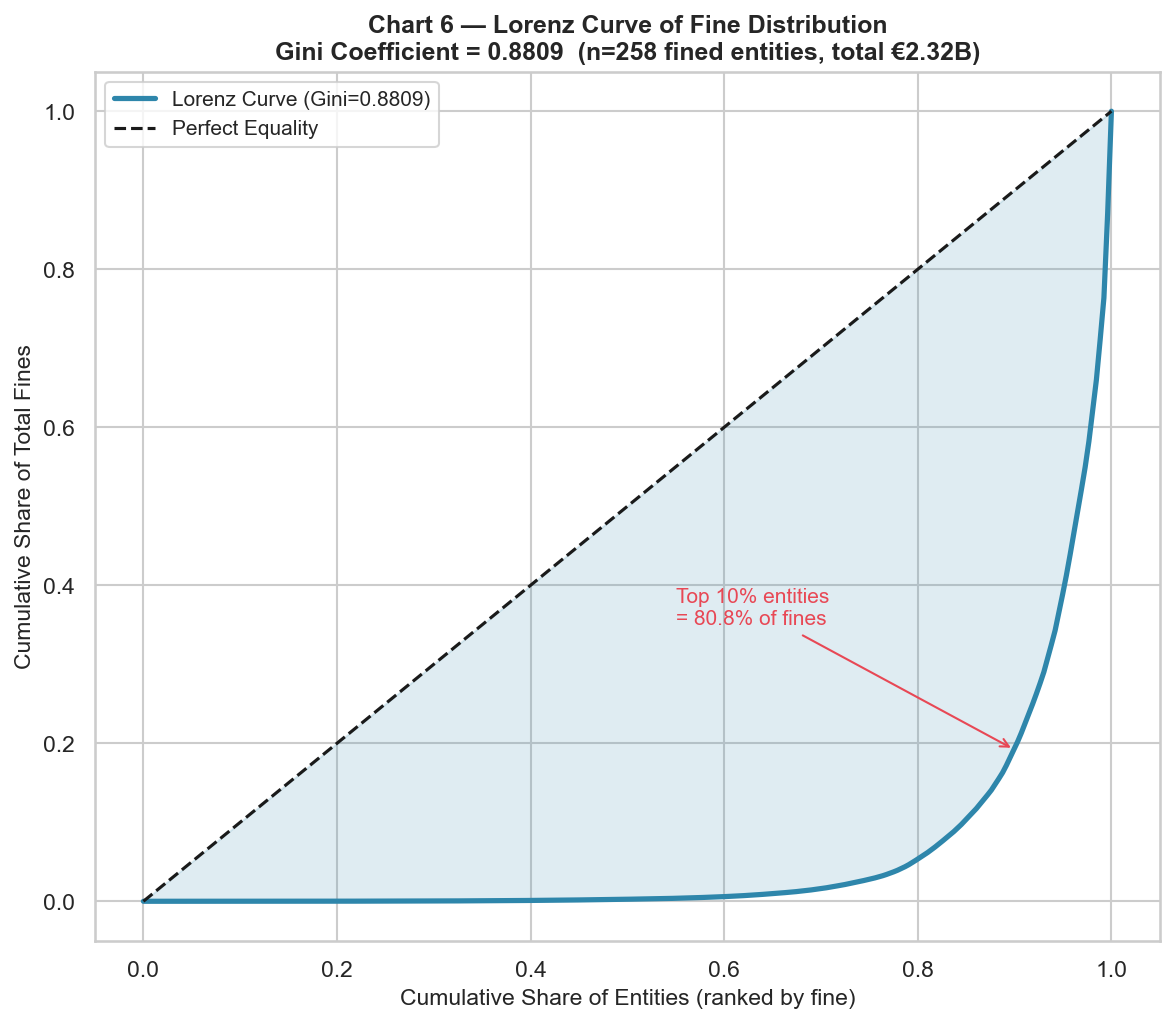
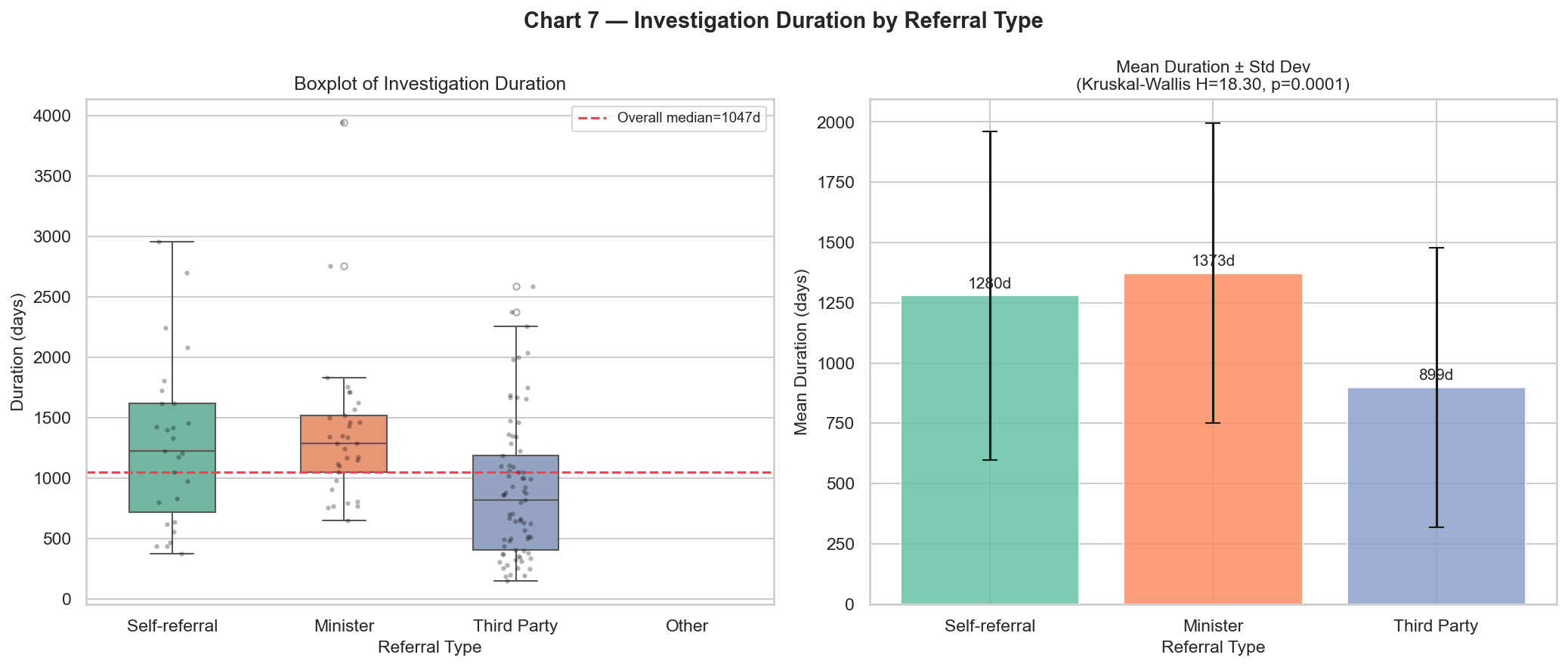
- Loaded the dataset, flattened the nested prosecuted-entity records, and produced an 11-panel statistical dashboard (distributions, Lorenz curve, OLS coefficients, sanction rate, recidivism premium…).
- Ran the analyses, drafted the charts, and emitted a PDF write-up.
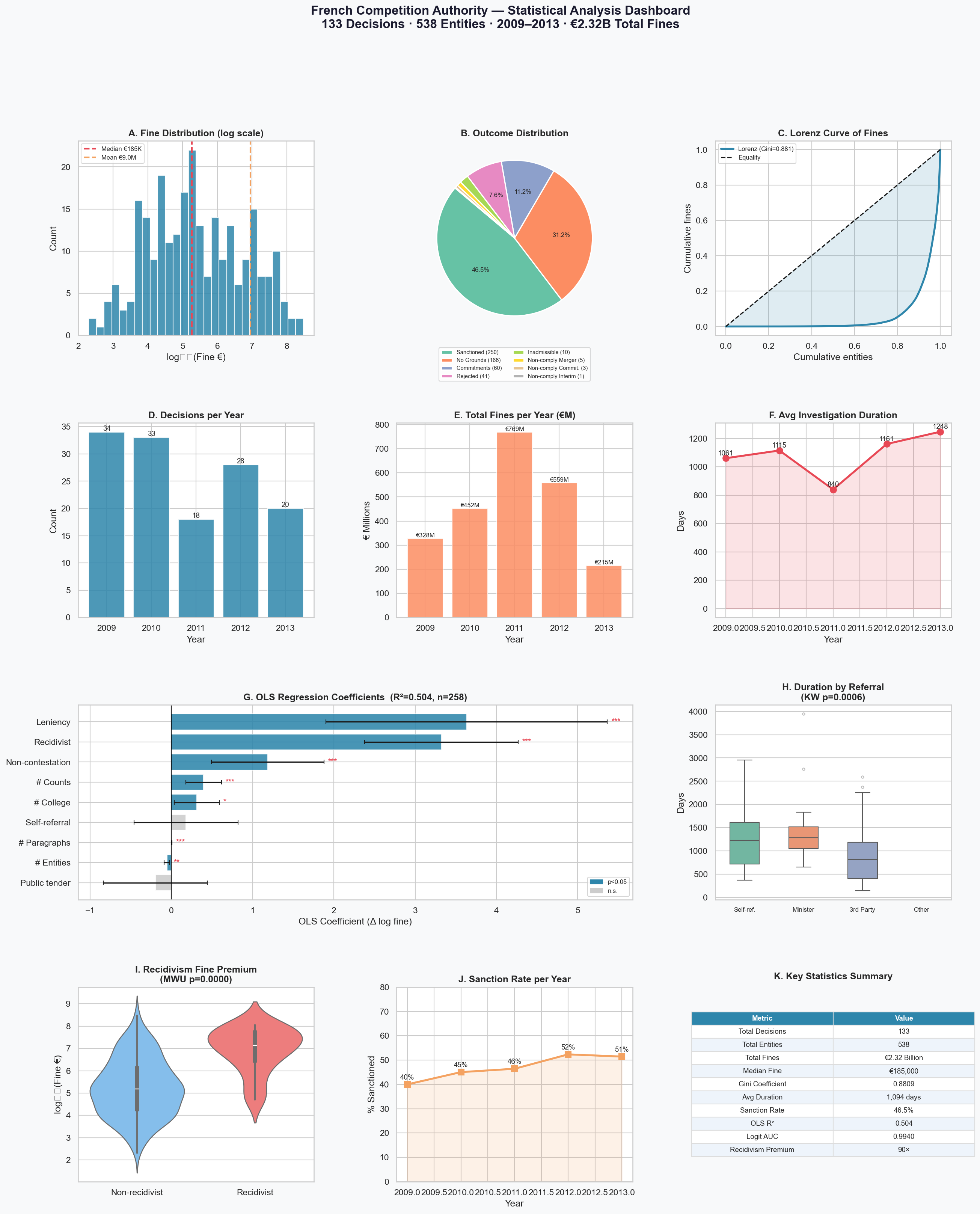
- Generated, among other things:
- 46.5% of prosecuted entities are sanctioned (
SANCT); 31% dismissed (NONLIEU). - Total fines 2009–2013 ≈ €2.32 B, with a Gini of 0.88 (more unequal than household income in every OECD country).
- Median fine = €185,000; mean = €9.0 M (skew ≈ 6.5).
- Recidivists pay ~90× the median fine of non-recidivists (Mann-Whitney p < 0.0001).
- OLS on log-fine: leniency (+3.64), recidivism (+3.32), non-contestation (+1.19), all p < 0.001. R² ≈ 0.52.
- Logistic regression for the probability of sanction: AUC ≈ 0.994 — the count of culpa charges (
n_culpa) is the strongest single predictor. - Minister referrals take 1,387 days on average vs. 965 for third-party referrals (Kruskal-Wallis p = 0.0006).
- 46.5% of prosecuted entities are sanctioned (
The eight charts the agent produced, in the order it generated them:
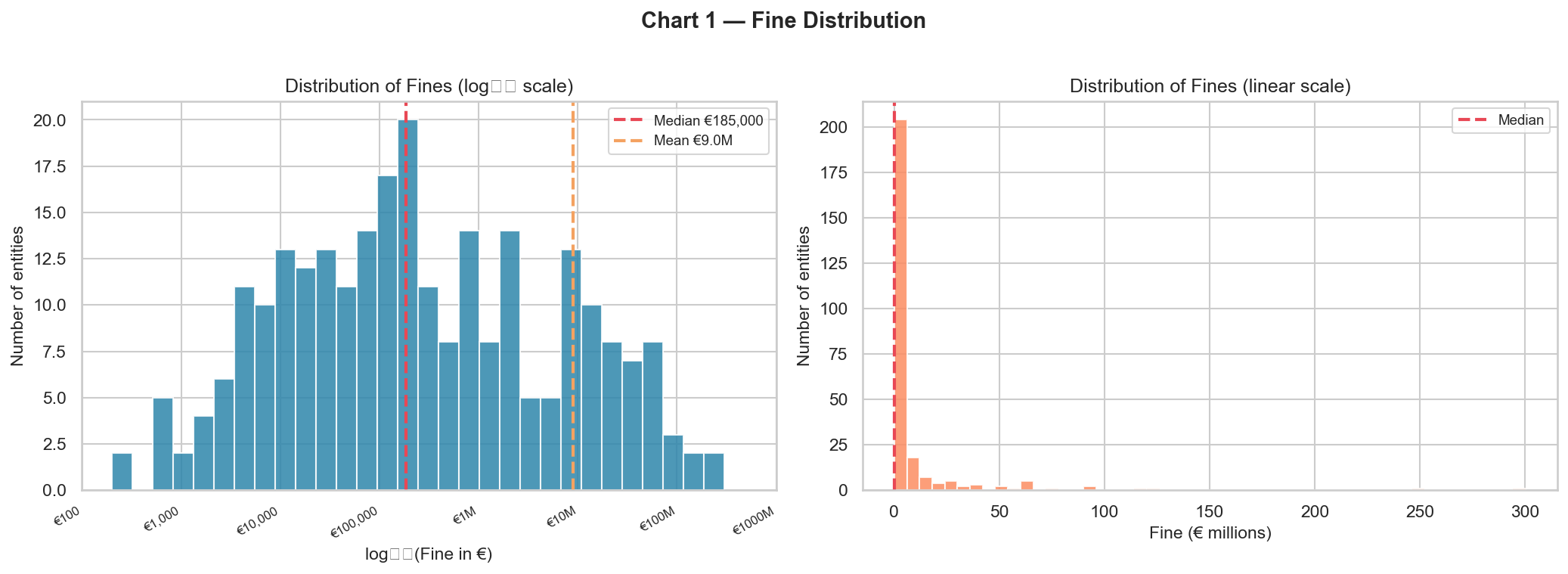
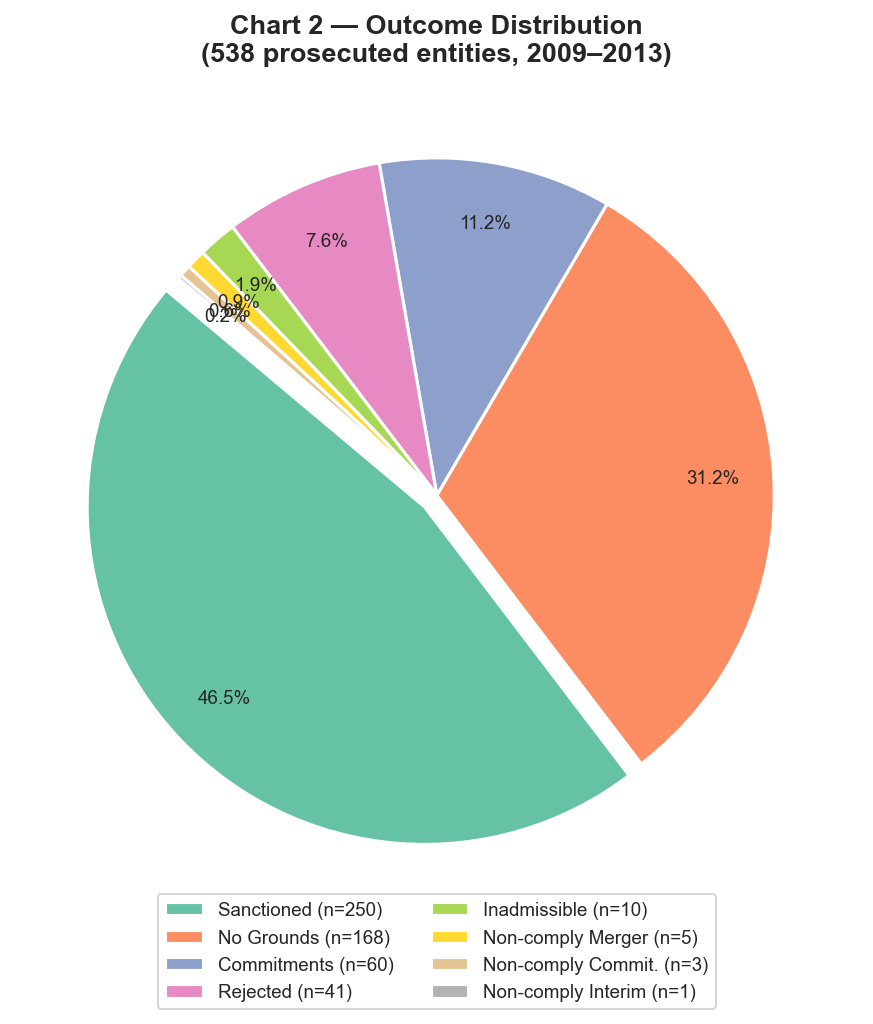
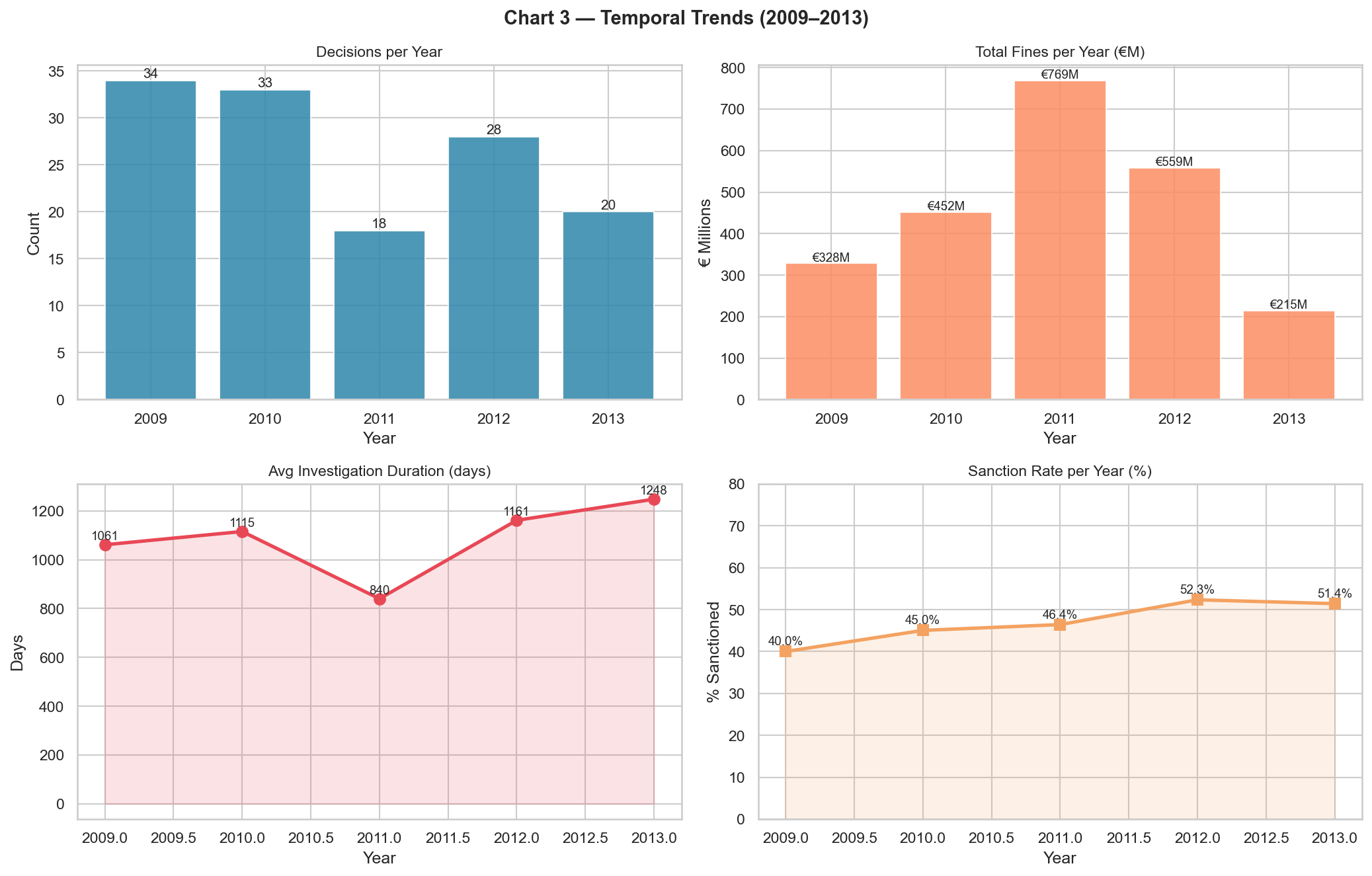
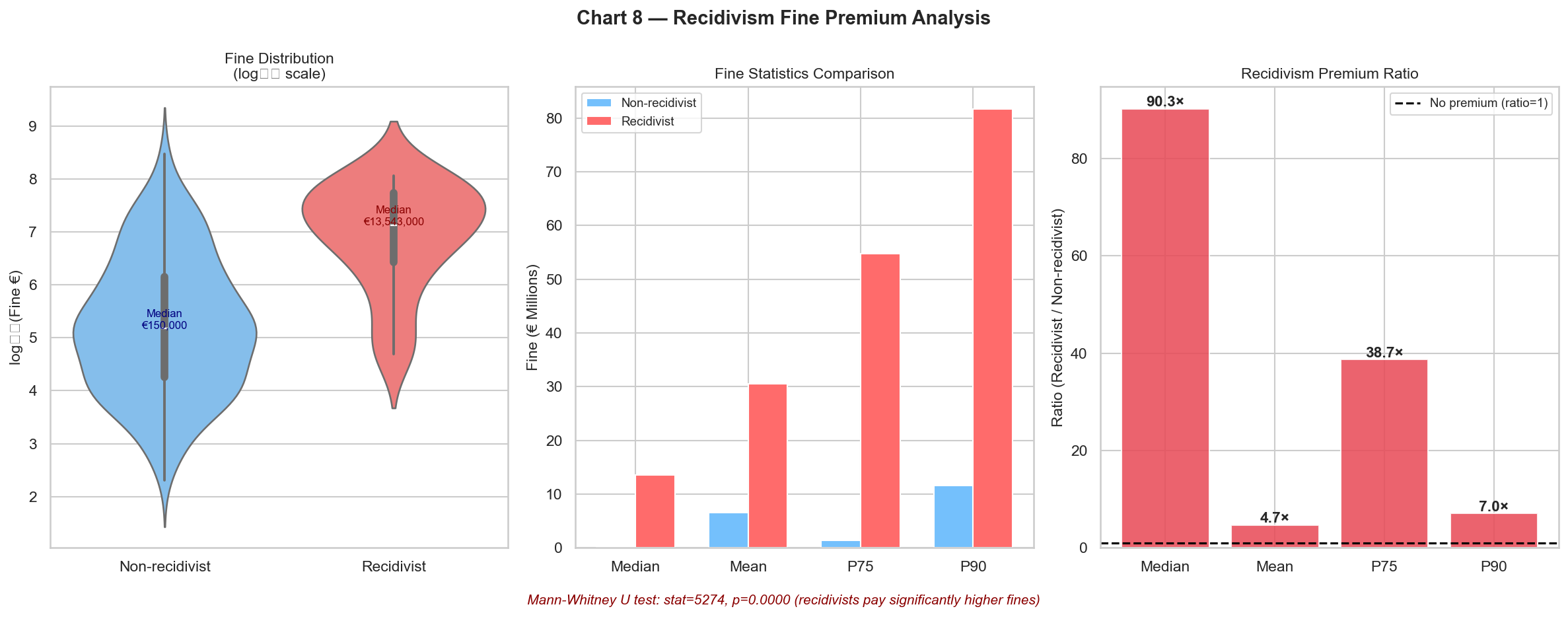
These are not findings I want to defend yet — they come from 130 decisions and need the bigger benchmark and the full extraction behind them. But they're a realistic preview of what a complete pipeline will yield, and every chart and number on that list was produced by the agent itself with one natural-language prompt.
5. What's next
A short, ordered list:
- Full-scale extraction — run the benchmark winner over all 1,900+ decisions.
- Agent evaluation — score the deep-research agent itself: faithfulness, reproducibility, and the quality of its econometric output. We need a benchmark for the agent, not just the extractor.
- Ontology extraction — lift the JSON schema into a proper typed ontology (entities, roles, relations).
- Knowledge graph in Neo4j — model everything as a graph DB to enable traversal, link prediction over cases and firms, and richer queries than a flat table allows.
- External merging — join
SIRENidentifiers to ORBIS / INSEE financials for causal-style impact studies. - Publish — push the dataset and benchmark to Hugging Face for openly reusable artifacts.
- Local CLI / web app — package the full pipeline (scrape → extract → analyse) so it runs end-to-end on a local machine, no cloud required.
Takeaways
- Structured output is the unlock. It's not glamorous, but constrained decoding is what makes "an LLM read this PDF" go from a demo to a pipeline. No regex parsing. No retry-on-malformed-JSON. Schema-typed records that you can store, query, and re-process.
- Open-source models are competitive. When
google/gemma-4-31b-ittops a leaderboard against frontier proprietary models on a serious task, the economics of "let's just run this over the whole archive" change completely. - The interesting layer is the agent. Extraction turns text into a dataset. The agent turns a dataset into a paper draft. That's where the time savings — and the methodological questions — live for the next phase of the project.
Code lives in two repositories I'll open up as the benchmark stabilises: fca-decisions-scraper (acquisition) and competition-ner-bench (extraction, evaluation, agent). If you work on legal NLP, structured extraction, or research agents, I'd love to compare notes.